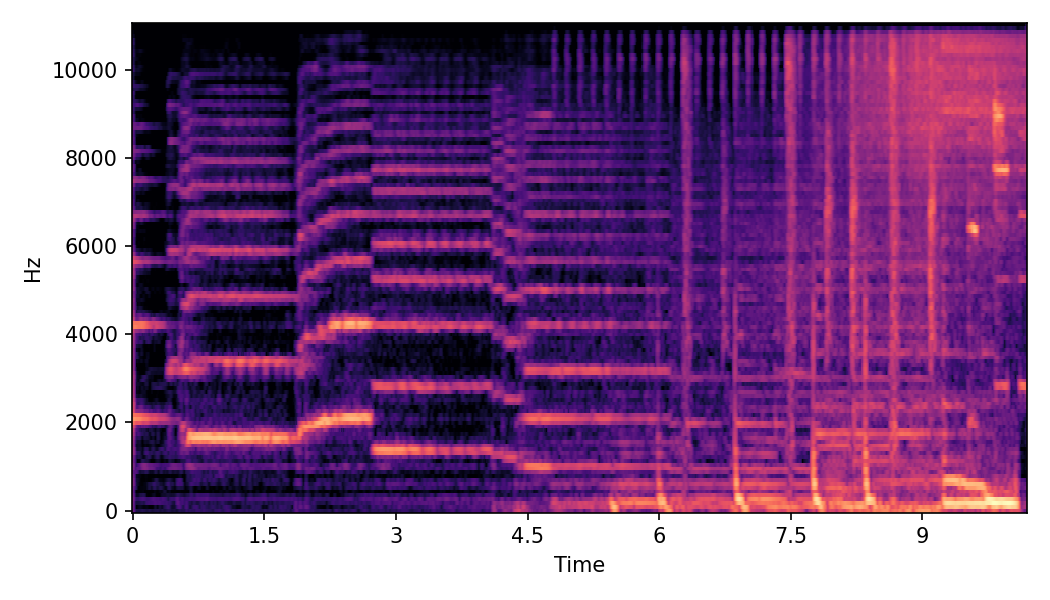
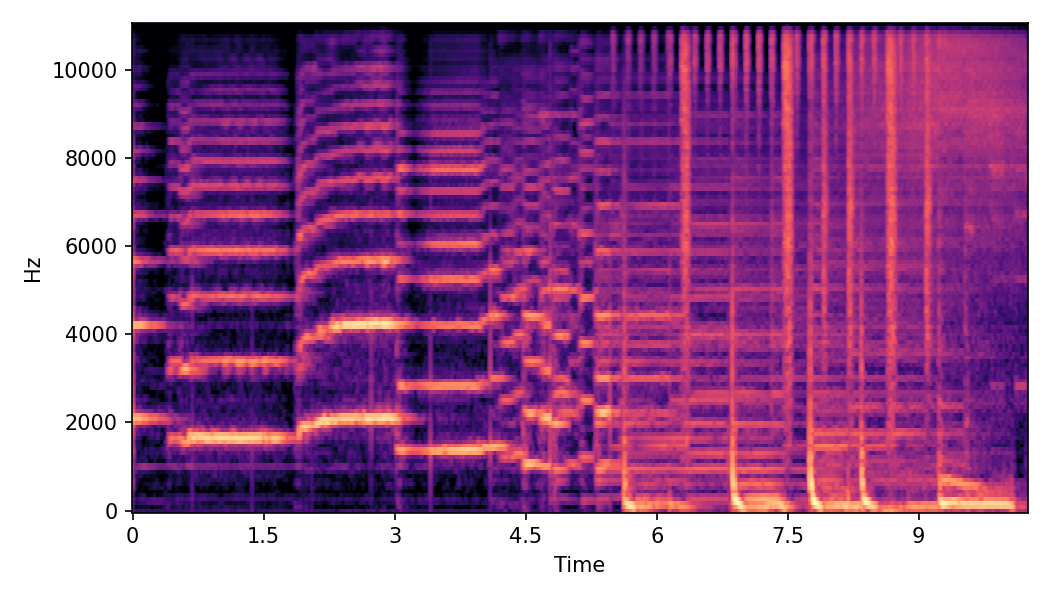
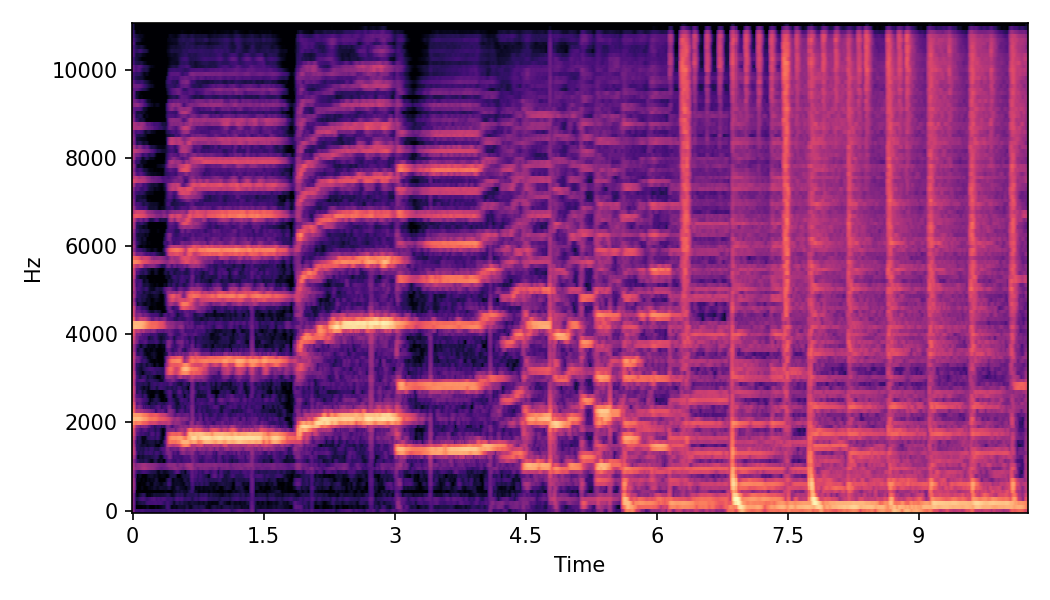
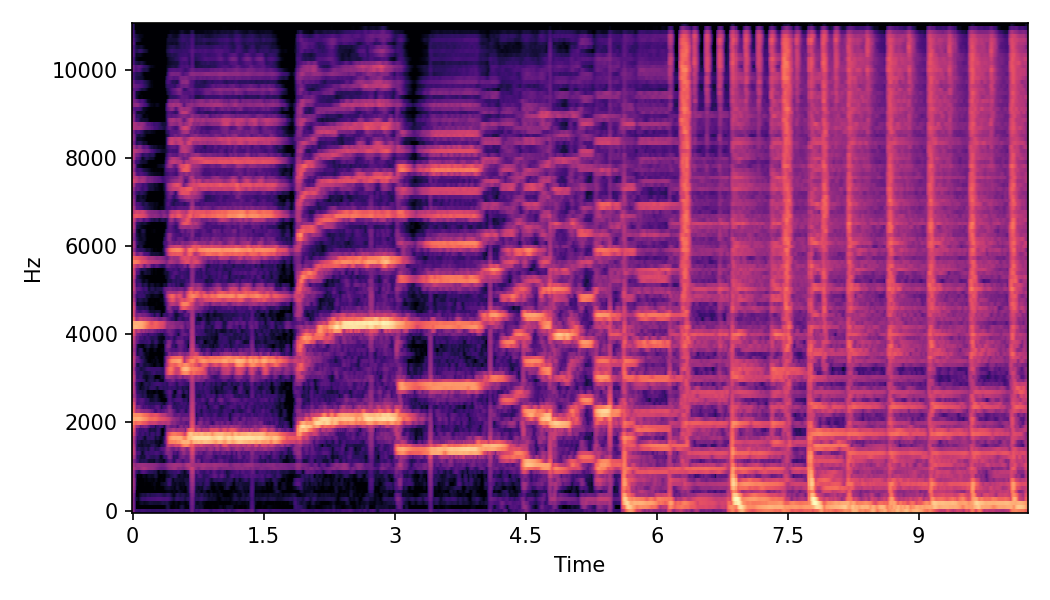
This page provides additional details and ablation study on Convex CFG scheduling used in SoundMorpher.
Background for Classifier-free Guidance (CFG).
Controllable generation can be achieved by using guidance at each sampling step in diffusion model. When a conditional and unconditional diffusion models are jointly trained, samples can be obtained by CFG [1]. In AudioLDM2 [2], the the conditional and unconditional noise esitimation becomes
\[
\hat{\epsilon}_{\theta}(z_t,t,E) := w \epsilon_\theta(z_t,t,E) + (1-w) \epsilon_\theta (z_t,t,\varnothing)
\]
where \(w\) determines the guidance scale.
Convex CFG scheduling.
Followin [3], we involve a convex CFG scheduling in SoundMorpher to boost morphing quality which is defined as
where \(w\) is the guidance scale, \(\alpha\) is the morph factor.\(w_{max}\) and \(w_{min}\) are predefined maximum and minimum guidance scales.
Ablation study on classifier-free guidance (CFG) scales
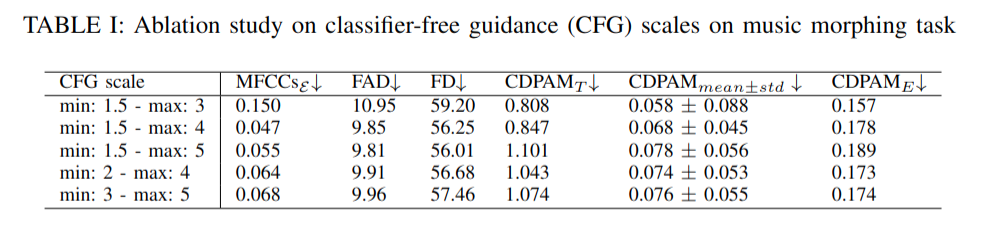
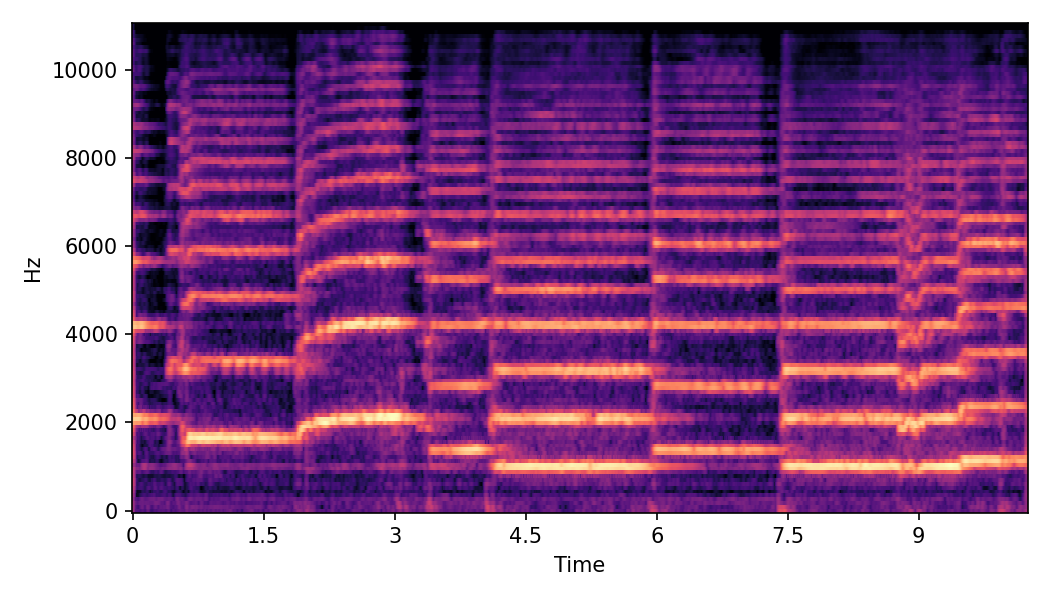
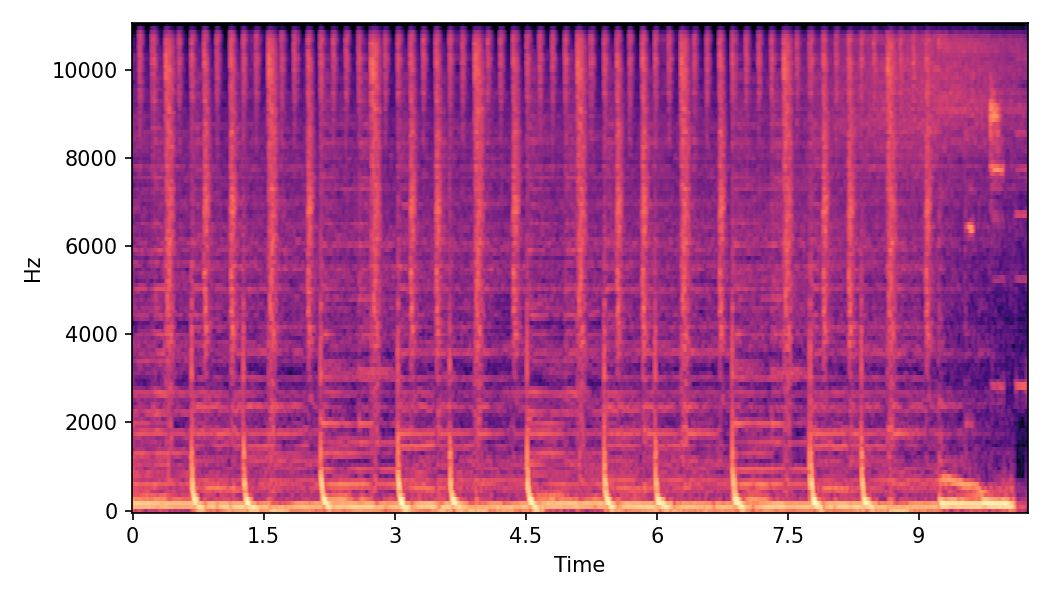
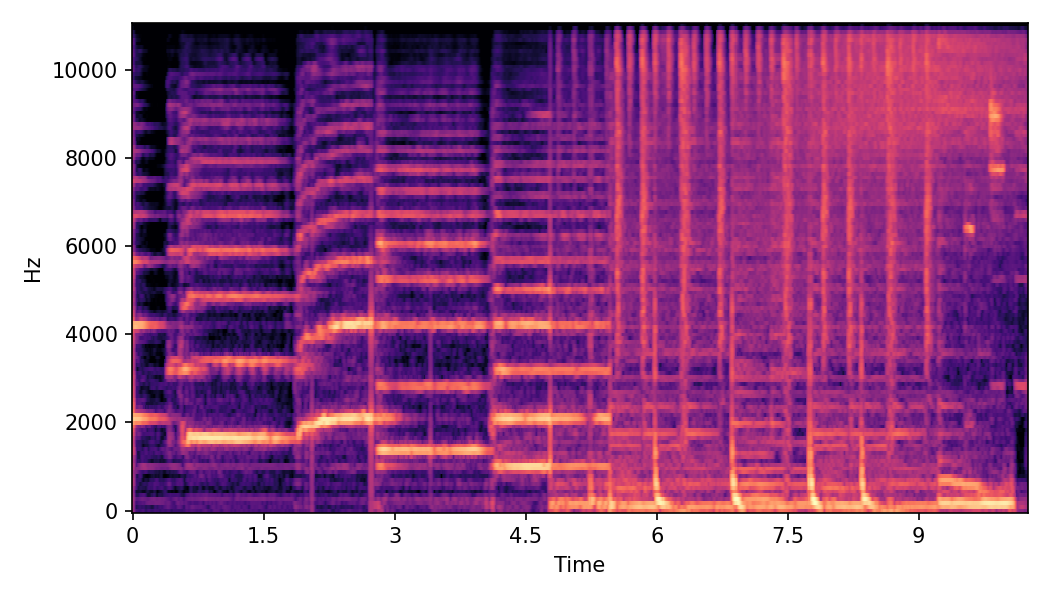
In this experiment, we explore impacts of CFG scales on SoundMorpher, we conduct an ablation study on music morphing task with \(N=15\) on different sets of max-min CFG scales in TABLE I. According to our experimental results, maximum scale controls correspondence quality and smoothness quality of morphed results, whereas higher maximum scale leads to a lower \(MFCCs_{\mathcal{E}}\) and higher \(CDPAM_{mean} \pm CDPA_{std}\). In contrast, minimum scale controls intermediate quality of morphed results, where higher minimum scale leads to higher \(CDPAM_{T}\).